More of a ‘programmy’ topic today – this one about storing hierarchical data (data that could represent a tree) as records in a relational database.
There’s plenty of information on the web about storing hierarchical data in SQL using these methods:
- Adjacency list
- Materialised paths
- Nested sets
The method I used in a personal project of mine, however, is different to all of these. Today I found this Evolt article, which pretty much describes the technique I’m using, calling it ancestor tables.
I don’t know if it’s just because I don’t know the right name for it, or if people just generally haven’t thought of it, but finding anybody using this method has been pretty difficult – for whatever reason, nested sets (which I believe has serious flaws) and materialised paths seem to be all the rage instead.
First, I’ll describe each of the alternative methods in brief. More information is available in this article from DBAzine, though you can find an easier to understand description of nested sets in this one from MySQL.
Brief descriptions
An adjacency list just means that for each node, you also store the ID of its parent node. It’s easy to write a query to find immediate parents or children of an node using this method, but finding a list of ascendents of descendents, including non-immediate ones, requires some sort of fancy recursion. That’s a well acknowledged limitation of this method, and if you look around the web you’ll find a lot of people pointing this out, at the same time singing the praises of nested sets as if they’re the only alternative.
A materialised path means that for each node, you store a string which represents the path to that node. For instance, the node with id 13 might have a path of ‘1.2.12’, meaning that it is the immediate child of 12, which is the child of 2, which is the child of 1. This opens up a few more possibilities in terms of efficient queries that can be made. For example, you can easily find all descendents of an node using a WHERE path LIKE ‘1.2.%’ type of syntax, or just WHERE path=’1.2′ if you only want immediate children. Efficiently finding ancestors is still a bit fiddly, as is moving an node to elsewhere in the table, but it’s not unmanageable. I actually think it’s a good solution.
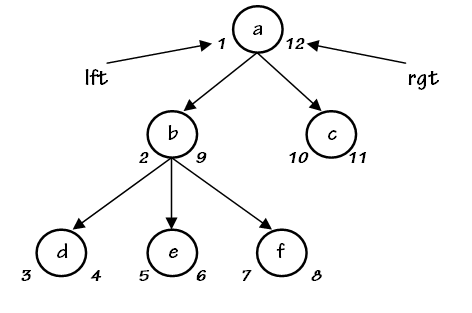
Nested sets are more complicated than any other method. For each node, you store two integers, which represent a ‘range’. The ‘root’ node of the tree contains the lowest and highest numbers of the whole tree, and each branch contains the lowest and highest number of that branch. It’s probably easiest to illustrate this with a diagram (which I found in this article). Each number between the lowest and highest is used once and only once in the whole tree. The major benefit to this is that it makes finding all descendents of a node fairly efficient. To find children of an node, just find all nodes WHERE leftvalue > parent.leftvalue AND rightvalue < parent.rightvalue. It’s highly inefficient, however, when you only want immediate children, ie only a single level of descendents. It also lets you down substancially when making any modification to any node in the tree; any creation, deletion or moving of an node will always require, on average, half of the rows in the whole table to be updated. Good if the tree is very small or you never plan to update it; bad otherwise.
{kind=link}
Variations of nested sets exist which attempt to solve some of its problems, but these tend come at the cost of even greater complexity. I was reading about a method with ever decreasing fractions for increasing levels of the tree earlier.
Ancestor tables
My ancestor tables method can probably be thought of as similar to a materialised path, in that it requires about the same amount of information, except that it doesn’t concatenate it all together into a string to be stored in a single column value, but represents each ancestor in its own row in a separate relation table:
- ancestor_ID (int)
- node_ID (int)
- level (int)
For each node added to the tree, you add rows to this ancestor table describing its ancestry. So for example, if node 13 is the child of 12, which is the child of 2, which is the child of 1, this would be represented in the ancestor table as:
| ancestor_ID | node_ID | level |
|---|---|---|
| 1 | 13 | 3 |
| 2 | 13 | 2 |
| 12 | 13 | 1 |
The total number of rows needed in this ancestor table is related to the number of ancestor-descendent relationships in the whole tree. If your average node is nested only 4 levels away from the root node, then you only need about 4 times the number of nodes. It’s much less even than O(n log n).
(When I do it, I also includes a 0th level for each node, where ancestor_ID equals node_ID and level is 0. There was only one edge case where this helped me for my specific project.)
The method allows for all of the following queries to be efficient, requiring no recursive joins or multiple queries.
- Find the parent of a node:
SELECT ancestor_ID FROM ancestors WHERE node_ID=<nodeid> AND level=1 - Find all ancestors of its node, including its parent, and each parent in turn:
SELECT ancestor_ID FROM ancestors WHERE node_ID=<nodeid>
- Find all the immediate children of a node:
SELECT node_ID FROM ancestors WHERE ancestor_ID=<nodeid> AND level=1 - Find all the descendents of a node, including all immediate children and their descendents:
SELECT node_ID FROM ancestors WHERE ancestor_ID=<nodeid>
As you can see, none of these queries need recursive joins, or require the database to inspect more rows than they need to, and none of them even require looking up certain information (such as the path to the requested node, or left and right values) before actually doing the query that returns the rows.
Add a LEFT OUTER JOIN to your main node table, and you can fetch all the necessary data about each node (name, properties, etc) in the one query.
You can even do efficient sorting via the same index used to fetch the rows, as long as you add columns to the ancestor tables for whatever data you want to sort on and use indexes wisely.
It also means that when inserting a new node, or making another edit to the tree, you do not have to modify the majority of the tree – only the entries in the ancestor tables that belong to that node. This is similar to the materialised paths technique, where you only need to update the path for the node you change.